How to Analyze Your Experiment Results
This guide helps you make better decisions by explaining how to interpret the results page of your experiment. It is intended for all users.
Background
This document shows how to logically analyze the results of AB testing, what data you can find on our platform, and how to conclude the impact of the experiments. Generally, we suggest that the experiment needs to run for at least 7 days (weekly period). You can read the experiment results in the following order:
- Read the Suggestion
- Check the Cumulative Exposures
- Read the Metric Values through Basic Analysis
Suggestions

The suggestion section gives you a high-level summary of your experiment based on the rules below. However, you may still need to combine this with the metrics performance details and your business logic to arrive at a final decision. The rules of the suggestion are as follows:

Cumulative Exposures

Cumulative Exposures show the number of cumulative unique users exposed to each group of the experiment daily. You can see whether the number of exposed users is as expected. More detailed information will appear when hovering over the graph.
The information on the right side shows the cumulative numbers of exposed users till today (or the end day of the experiment).
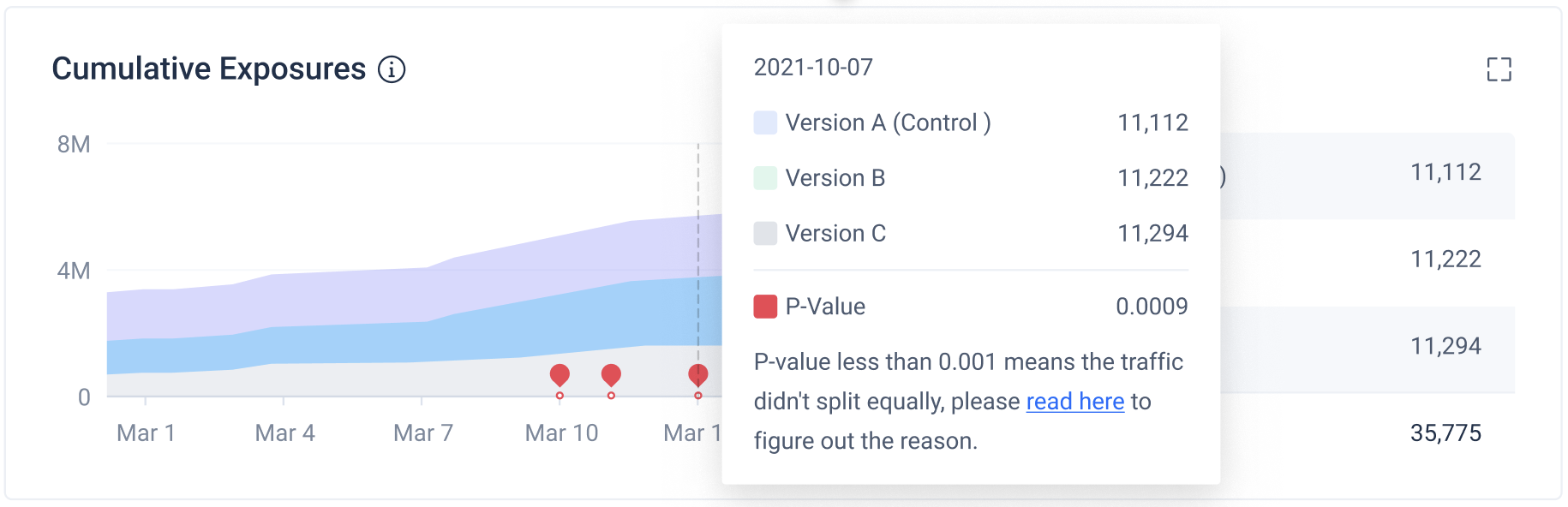
The red points appear when Sample Ratio Mismatch (SRM) happens. This is caused by the ratio of the cumulative exposures among the experiment groups not matching their allocation on the experiment setup page. You can hover on the red points and view the reasons and solutions of SRM.
Basic Analysis

While you can get a brief understanding of the experiment results through Suggestion and Cumulative exposure, if you would like to have a more detailed and scientific analysis, you could go through the basic analysis:
① Change the Groups
Comparing group defaults to be the first treatment group, baseline group defaults to be the control group. You can change the groups or even compare multiple treatment groups with the control group at the same time.
② Time Filter
You are able to filter the time range and view the results. Note that the start time is the same as the start time of the experiment and can not be changed.
③ Metrics List
You can filter, search, or perform other actions through the metrics list.
④ Metrics Values
The box-plot shows the relative difference and confidence level.
- Relative Difference = (metric value of treatment group - metric value of control group)/metric value of control group
- A confidence interval is a range of values, bounded above and below by two relative differences, that would likely contain the true relative difference of the two experiment groups, which is unknown. Confidence level refers to the percentage of probability, or certainty, that the confidence interval would contain the true population parameter when you draw a random sample many times. Or, in the vernacular, "we are 95% certain (confidence level) that most of these samples (confidence intervals) contain the true population parameter."
The meanings of different colors of the box plots:
- Green: Relative difference is significantly positive
- Red: Relative difference is significantly negative
- Grey: Relative difference is not significant
Furthermore, more information about metric values will appear when you hover over the box plots:
- The metrics values of the treatment and control group
- P-value
- The probability of beating the baseline based on Bayesian inference
- Click "detail" to see the details of metrics, as well as the trends of metric values.
⑤ Zoom In/Out
You can zoom in/out the box-plot area.
⑥ View More Metrics
Some box plots might be out of the display area after zooming in. You can click the prompted triangle arrow to view the enlarged box plots.
⑦ Trends
You can observe the trend chart of the relative difference of non-cumulative metrics, and click the trend chart to view the details of the metric trend fluctuation, as shown in the figure below: 
⑧ Change the Metrics
Here you can switch to compare the metrics of the current two groups.
⑨ P-Value
A/B testing is essentially a hypothesis test. The null hypothesis states that there is no statistical significance between two variables. The opposite of a null hypothesis is an alternative hypothesis. P-value is the probability that the null hypothesis is more extreme than our experimental result. We use the p-value to judge whether there is enough evidence to reject the null hypothesis. When the null hypothesis is true, the p-value is small enough that it means the probability of the experimental result appearing is very small, so that we can reject the null hypothesis. Let's use the coin example to explain:
- Experimental result: Toss a coin five times, and the results are all heads.
- Null hypothesis: There are fair coins, which means it has a 50% chance of landing heads up and a 50% chance of landing tails up.
- Alternative hypothesis: There are unfair coins. If the null hypothesis is true, it means the coin is fair, and the probability of our observation being more extreme than the experimental result is only p=0.03<0.05, which is a very small probability event. Since p<0.05, we have enough evidence to reject the null hypothesis. When the p-value is less than the significance level (default is 0.05), it is considered that there is no difference between the control and the treatment. In ABC, the metric value box plots are distinguished by color, a green box plot indicates positive significance, and a red box plot indicates negative significance.
⑩ Minimum Detectable Effect (MDE)
The minimum Detectable Effect (MDE) is the relative difference of the metric that can be detected effectively under the experiment conditions. Once the MDE is smaller than the threshold (the default value is 1%) which is set in the metric configuration, a blue tick will appear on the right side of the MDE, which means the sample size is sufficient. At this time, the significant difference is the most reliable and can be used as the basis for experimental decision-making.
Cumulative Data and Non-Cumulative Data
In the Basic Analysis, the relative differences shown are based on cumulative data. In the metric details card, we also provide the trend of metric relative difference based on both cumulative and non-cumulative data. Here is the statistical definition, take the average metric as an example:
- Non-cumulative data: The numerator is user behavior data sum by day, and the denominator is the number of users after removing the duplication by day, e.g. average watch time per person.
- Cumulative data: The numerator is the sum of user behavior data over multiple days, the denominator is the number of users after deduplication. For example: The table below shows the watch time per user per day,

Accordingly, we calculate cumulative and non-cumulative data of the average watch time for each day in the following ways:  Generally, we recommend the cumulative data. Learn More
Generally, we recommend the cumulative data. Learn More
More Functions
Significance Settings

Significance Level (α)
Significance level, also known as alpha or α, is a measure of the strength of the evidence. If the p-value is less than your significance level, you can reject the null hypothesis and conclude that the effect is statistically significant. The significance level is the probability of rejecting the null hypothesis when it is true. For example, a significance level of 0.05 indicates a 5% risk of concluding that a difference exists when there is no actual difference. The default value of the significance level is 5%.
Statistical Power (1-β)
Statistical power is the probability of not making a Type II error. For example, a study that has an 80% power means that the study has an 80% chance of the test having significant results when there is an actual difference. The default value of the statistical power is 80%.
Multiple Testing Corrections
Multiple testing corrections adjust p-values derived from multiple statistical tests to correct the occurrence of false positives. In the context of an A/B test, false positives are erroneous results where a non-existent effect or difference between two tested groups is mistakenly identified as significant.
Download Results
 Click the download button and download the data of the results
Click the download button and download the data of the results
Share the Results
 Click the share button and copy the link of the current page
Click the share button and copy the link of the current page
Q&A
Based on the instructions, we can solve a series of problems such as whether the impact of a strategy is statistically significant, and whether the improvement of the core metrics meets expectations. However, we may also have some questions:
Q1: What should I do if there is no statistically significant metric difference between the treatment group and the control group?
- When the MDE is greater than the relative difference, it's likely that the sensitivity of the experiment is not high enough and it is necessary to continue the experiment, increase the sample size, and reduce the MDE.
- When the MDE is smaller than the relative difference and the metrics are not statistically significant different, there is also a type II error possibility (default the probability of 20% ), meaning the test fails to detect the significance despite its existence.
Q2: If there is no statistically significant difference about the metric between the treatment group and the control group,can I modify the start calculation time of the experiment when analyzing the experimental result to make the metric significant?
- No, it is an unreasonable operation.
- We do not recommend modifying the start calculation time of the experiment after observing the experimental results, because it could lead to wrong experimental conclusions. The scientific observation method requires the hypothesis before the conclusion, rather than simply picking out favorable conclusions from experimental result.
Q3: Some of the target metric relative differences are positive and some are negative, what should I do?
- In this case, the experimenter needs to measure the benefits of the experiment strategy based on the understanding of the product, and whether it is worth launching. There is a trade-off between the experimental benefits and the cost.
Q4: If there is statistically significant difference of the metric between the treatment and the control group, and the increase in relative difference has met the expectations. Can I conclude that this experimental strategy must be effective?
- Not necessarily. The experimental results only measures the treatment effect during the experimental period. We should also focus on the long-term gain.
- For example, in a travel software, the treatment group changed the algorithm of hotel ranking, so it is necessary to wait until the user checks in before fully evaluating the experimental strategy, which will take long time. We can 1. Carry out the experiment for a longer period of time. 2. Design metrics that can reflect the long-term impact.
Q5: What's the maximum duration of automatic pre-computation for experiment results?
- The cumulative data can only be stored up to 30 days after the start of the experiment. If it exceeds 30 days, you need to seek customer service support.
Q6: Can I still see the experimental result after the experiment is offline?
- Historical results will be displayed, but the newly added metrics after the experiment is offline will not be displayed.