BigQuery 连接
本文档将引导您完成 ABetterChoice 与 Google BigQuery 之间的数据连接配置。整个过程包含以下 5 个步骤,预计耗时 10–15 分钟。
流程总览
- 在 ABetterChoice 平台启用 BigQuery 数据源
- 授权 ABetterChoice 代理访问您的 GCP 服务账号
- 为服务账号授予 BigQuery 权限(用于查询和读写数据集)
- 为服务账号授予 Dataproc 权限(可选,仅 HTE 分析需要)
- 在 ABetterChoice 平台填写连接信息,完成连接
在开始之前,请确认您已经准备好一个具备管理员权限的 GCP 项目,以及一个用于本次连接的 GCP 服务账号。
步骤 1 · 在 ABetterChoice 平台启用 BigQuery 数据源
打开 ABetterChoice 项目设置页面,进入「数据源」配置区,选择 BigQuery 作为数据源类型并启用。
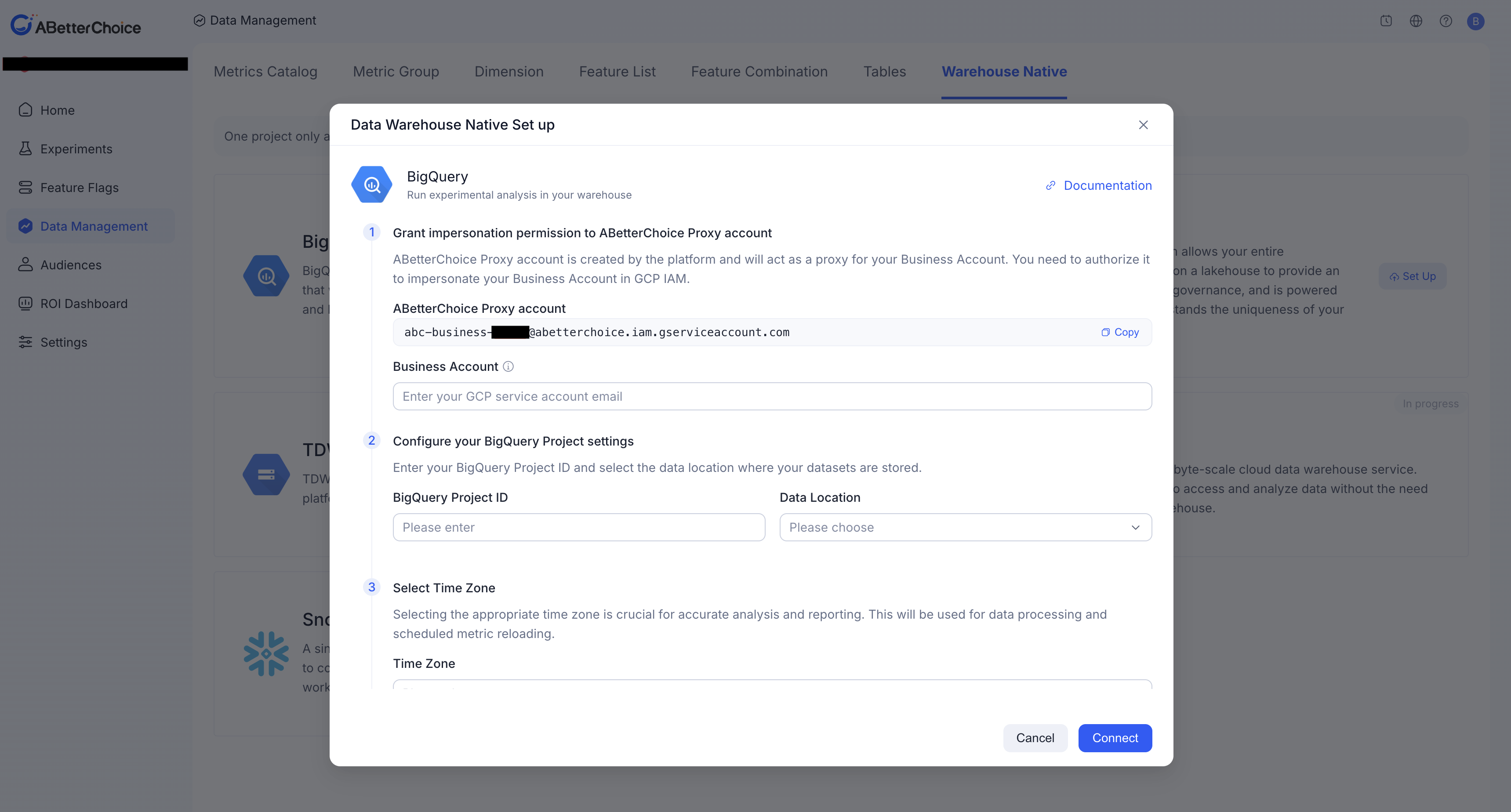
启用后,平台会引导您进入连接信息填写页面。请保持当前页面打开,方便步骤 5 回填信息。
步骤 2 · 授权 ABetterChoice 代理访问您的 GCP 服务账号
为了让 ABetterChoice 能够安全地代理您的身份访问 BigQuery 数据,您需要在 Google Cloud 控制台中完成以下授权配置。
第 1 步:进入服务账号详情页
打开 GCP 控制台的 IAM & Admin / Service accounts 页面,在列表中筛选并选中您希望授权的服务账号,点击进入详情页。
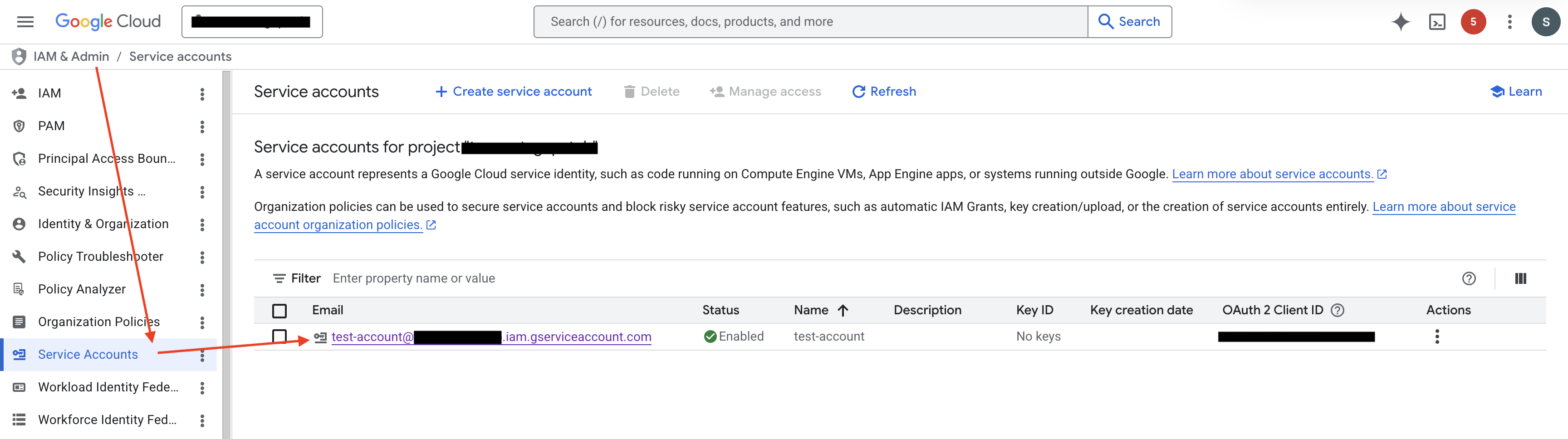
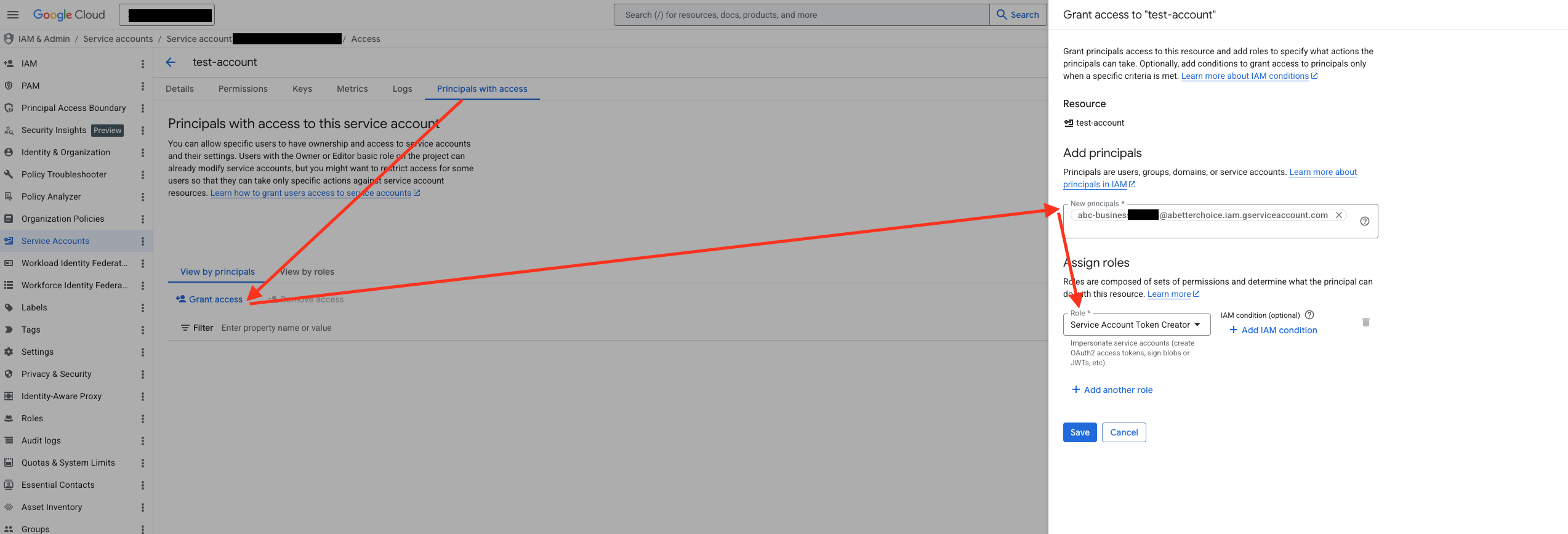
第 2 步:为 ABetterChoice 服务账号授予 Token Creator 角色
在详情页中切换到 Principals with access(权限)标签页,点击 Grant Access(授予访问权限),将 ABetterChoice 服务账号添加为主体(Principal),并授予 Service Account Token Creator(服务账号令牌创建者)角色。
该角色允许 ABetterChoice 在需要时为您的 GCP 服务账号创建短期访问令牌,从而以您的身份安全地访问 BigQuery,无需共享长期密钥。
步骤 3 · 为服务账号授予 BigQuery 权限
完成代理授权后,还需要为您的 GCP 服务账号授予 BigQuery 的访问权限,以便 ABetterChoice 能够运行查询并读写所需的数据集。请依次完成以下三步:
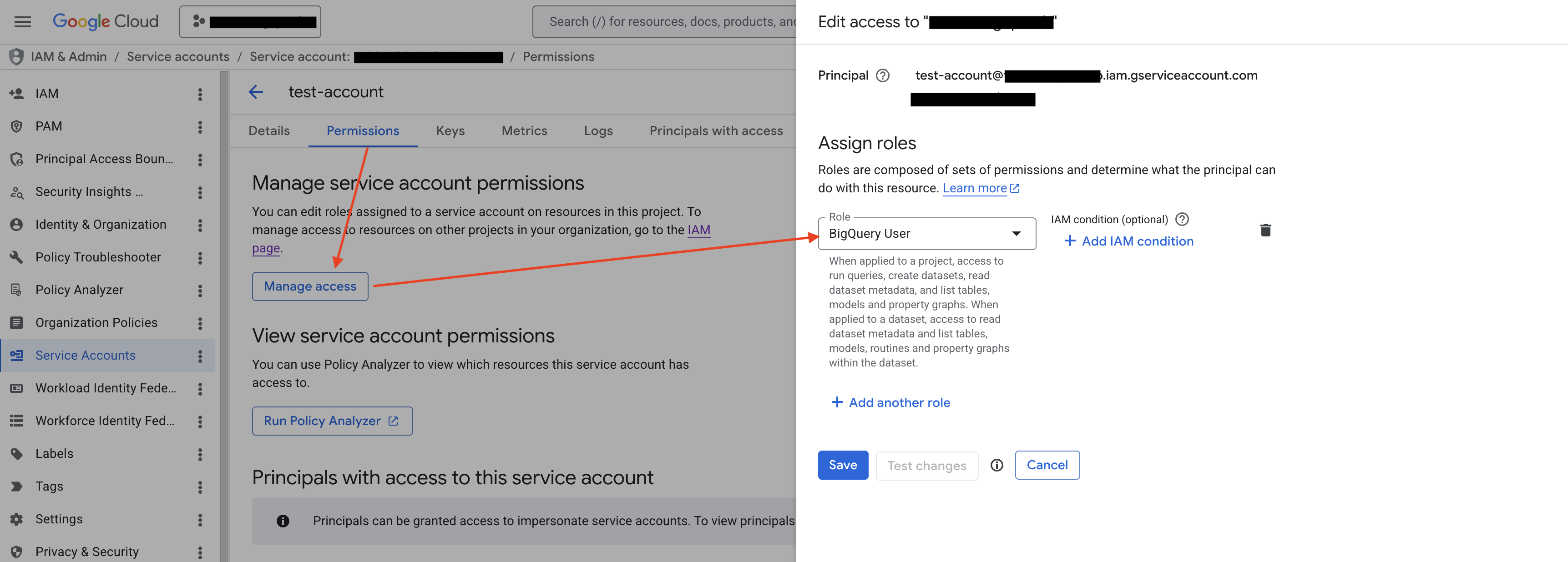
第 1 步:为服务账号授予 BigQuery User 角色
回到您的 GCP 服务账号详情页(即步骤 2「第 1 步」打开的页面),切换到 Permissions(权限)标签页,在 Manage service account permissions 区域点击 Manage access(管理访问权限)。在右侧弹出的 Edit access 面板中,确认 Principal 为当前服务账号自身,在 Assign roles 下选择 BigQuery User(BigQuery 用户)角色,点击 Save 保存。
该角色用于在 BigQuery 项目中创建和运行查询作业(Job),是后续所有数据操作的基础。
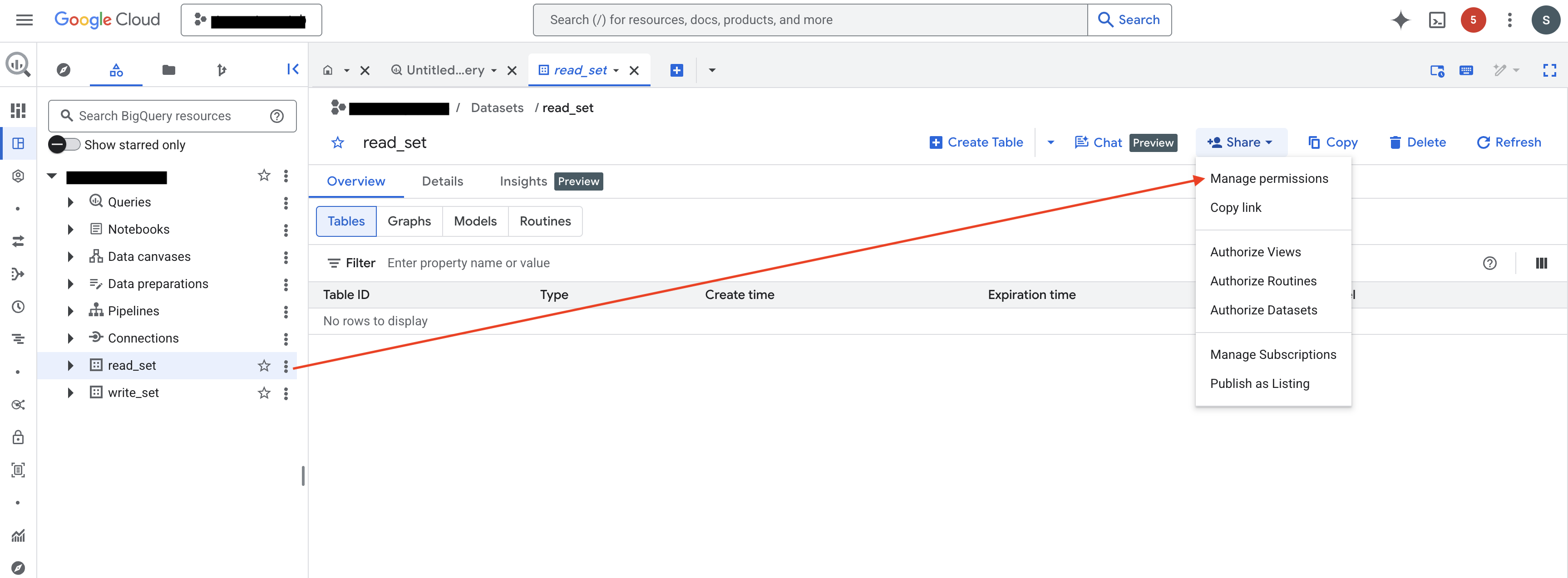
第 2 步:在数据源数据集上授予 BigQuery Data Viewer 角色
导航到 BigQuery Studio,选中您希望 ABetterChoice 访问的数据集,依次点击 Sharing → Permissions → Add Principal,将您的服务账号添加为主体,并授予 BigQuery Data Viewer(数据查看者)角色。
对所有希望作为指标数据源的数据集,重复执行此操作。
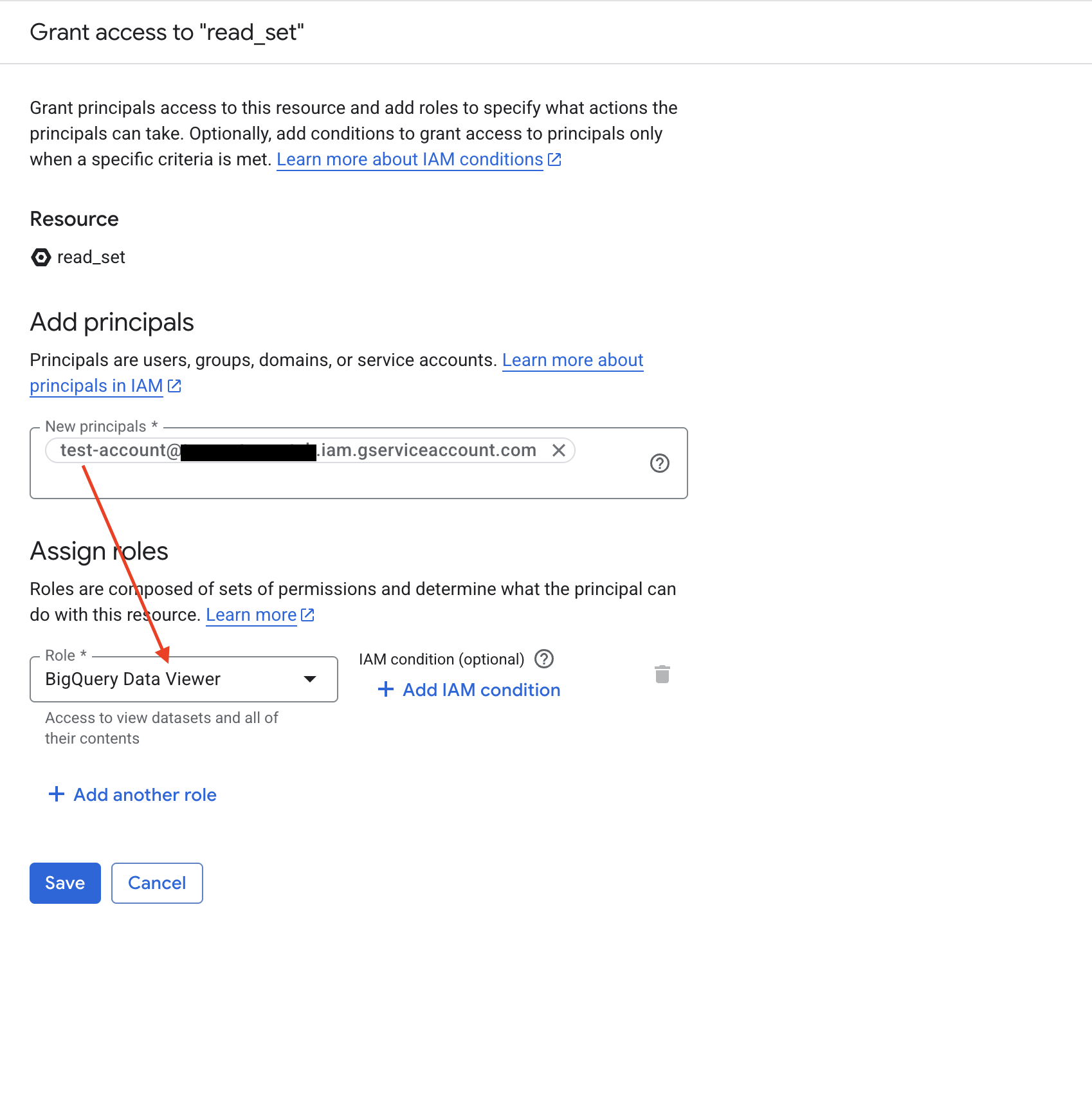
第 3 步:在临时数据集上授予 BigQuery Data Editor 角色
ABetterChoice 在运行查询时需要一个数据集用于保存临时表(分配表)和物化结果。请在 BigQuery Studio 中选择或新建一个专用于此目的的数据集,按同样的方式将您的服务账号添加为主体,并授予 BigQuery Data Editor(数据编辑者)角色。
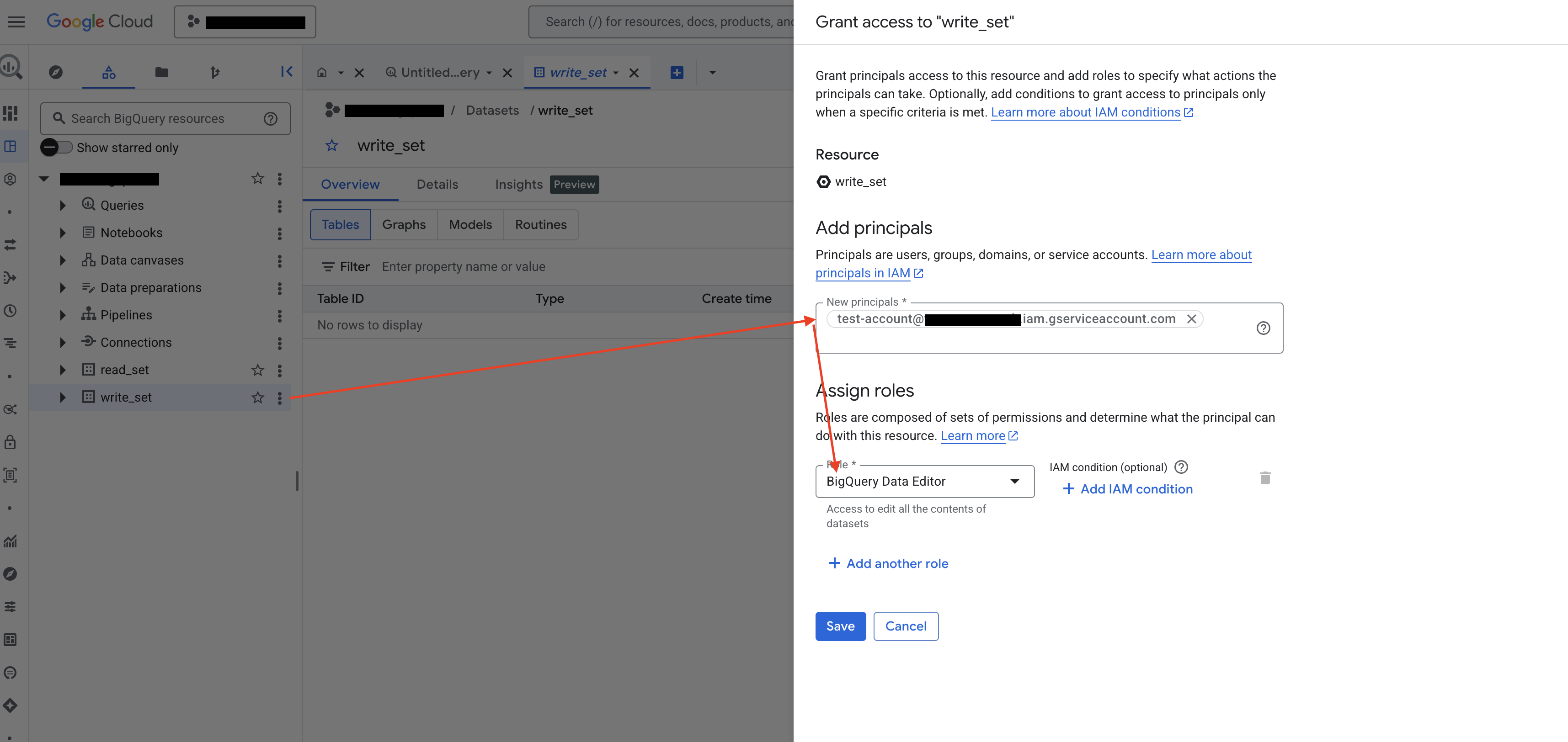
请记录该数据集的 ID,步骤 4 中填写 BigQuery DataSet 字段时会用到。
完成以上三步后,您的服务账号就具备了运行查询、读取数据源、以及物化结果所需的全部权限。
步骤 4 · 为服务账号授予 Dataproc 权限(可选 · HTE 分析)
仅当您需要在 ABetterChoice 中使用 HTE(Heterogeneous Treatment Effect,异质性因果效应)分析 时才需要执行此步骤。HTE 分析依赖 Google Cloud Dataproc 运行分布式计算作业,因此需要您的服务账号具备相应的 Dataproc 权限。如果您暂不使用 HTE 分析,可以直接跳到步骤 5。
第 1 步:在项目中启用 Dataproc API
打开 GCP 控制台的 Cloud Dataproc API 详情页,确认其状态为 Enabled(已启用)。如果尚未启用,请点击 Enable 按钮开启。
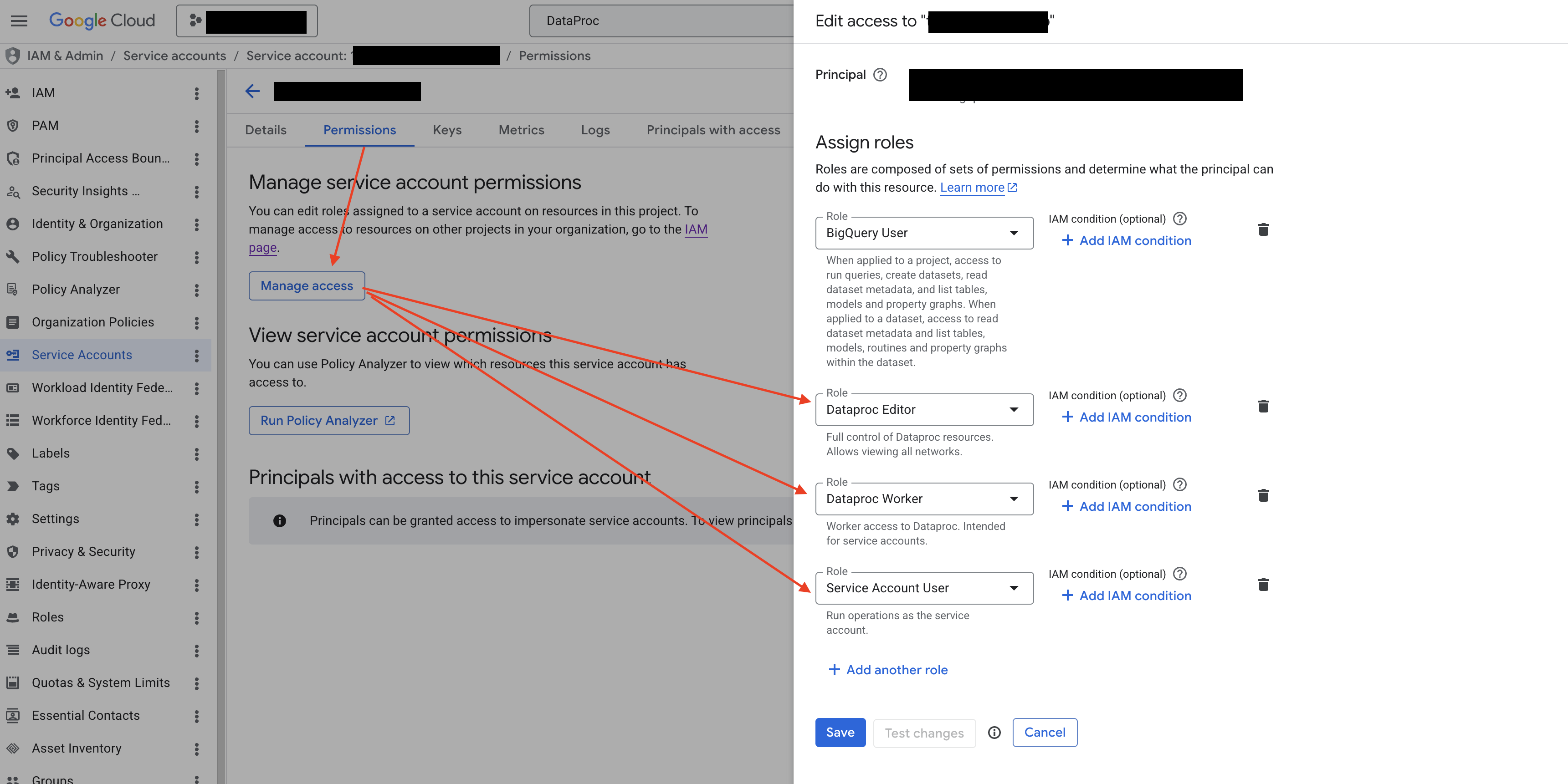
第 2 步:为服务账号授予 Dataproc Editor、Dataproc Worker 与 Service Account User 角色
回到您的 GCP 服务账号详情页(即步骤 2「第 1 步」打开的页面),切换到 Permissions(权限)标签页,在 Manage service account permissions 区域点击 Manage access(管理访问权限)。在右侧弹出的 Edit access 面板中,确认 Principal 为当前服务账号自身,依次添加以下三个角色,然后点击 Save 保存:
- Dataproc Editor(
roles/dataproc.editor):用于创建和管理 Dataproc 集群、提交计算作业。 - Dataproc Worker(
roles/dataproc.worker):Dataproc Serverless(Batch)作业的"运行身份"所需角色,为 Spark Driver / Executor 提供访问 Compute、Cloud Storage、Logging 等资源的最小权限。缺失时 Batch 作业会在启动阶段直接失败。 - Service Account User(
roles/iam.serviceAccountUser):允许 Dataproc Batch 启动 Worker VM 时以该服务账号身份运行(即iam.serviceAccounts.actAs权限)。
这三个角色管的是完全不同的事,缺一不可:
Dataproc Editor决定"有没有资格调用 Dataproc API 提交作业",Dataproc Worker决定"Worker 启动后是否拥有执行 Spark 作业所需的资源权限",Service Account User决定"能否把该服务账号附加到 Dataproc Worker VM 上运行"。少配Service Account User时,作业能进队列但 worker 起不来,会报PERMISSION_DENIED: ... iam.serviceAccounts.actAs;少配Dataproc Worker时,worker 能起来但作业会因为无法读写中间数据、写日志而失败。
第 3 步:准备 Dataproc 使用的 VPC 子网
ABetterChoice 在提交 Dataproc Batch(Serverless)作业时未显式指定 VPC 时,默认会使用项目中名为 default 的 VPC 网络下、与作业 region 同区的子网。请确保以下条件满足:
- 项目中存在
defaultVPC 网络。 打开 VPC networks 页面进行检查。若不存在(例如此前被删除或组织策略禁用了自动创建),请点击 Create VPC network,名称填写default,子网创建模式选择 Automatic(自动),完成创建。 - 作业所在 region 的子网已启用 Private Google Access(专用 Google 访问)。 进入对应子网详情页,将 Private Google access 设置为 On。这是 Dataproc Serverless 访问 Google API 和拉取镜像的必要条件。
- 防火墙规则允许子网内部通信。 确保存在
default-allow-internal等内部互通规则(自动创建的defaultVPC 默认带有该规则;如使用自定义网络,请手动放开同子网 TCP/UDP/ICMP 全端口)。
请记录该子网的完整 URI(格式如
projects/<PROJECT>/regions/<REGION>/subnetworks/<SUBNET>),步骤 5 中填写 Subnetwork URI 字段时会用到。若您的组织策略不允许创建default命名的 VPC,请联系 ABetterChoice 支持团队,我们可以在作业配置中显式指定自定义 VPC/子网。
完成以上步骤后,ABetterChoice 即可代理您的服务账号在 Dataproc 上运行 HTE 分析所需的计算作业。
步骤 5 · 在 ABetterChoice 平台填写连接信息
回到步骤 1 打开的 ABetterChoice 数据源配置页面,按下方字段说明依次填写。
5.1 字段说明
| 字段 | 是否必填 | 说明 |
|---|---|---|
| Business Account | 必填 | 您的 GCP 服务账号 email,格式形如 xxx@<project>.iam.gserviceaccount.com,即步骤 2 中被授权的目标服务账号。 |
| BigQuery 项目 ID | 必填 | BigQuery 数据所在的 GCP 项目 ID。查找方式见 5.2 如何查找 BigQuery 项目 ID。 |
| Data Location | 必填 | BigQuery 数据集所在的区域(如 US、asia-east1)。查找方式见 5.3 如何查找数据位置。 |
| 时区(Timezone) | 必填 | 用于解析时间字段和报表展示的时区,例如 Asia/Shanghai、UTC。建议与业务数据的时区保持一致。 |
| BigQuery DataSet | 必填 | 用于保存临时表和物化结果的数据集 ID,即步骤 3「第 3 步」中授予 BigQuery Data Editor 角色的那个数据集。 |
| Subnetwork URI | 可选 | 仅 HTE 分析需要。Dataproc 作业使用的 VPC 子网完整 URI,即步骤 4「第 3 步」中准备的子网。格式:projects/<PROJECT>/regions/<REGION>/subnetworks/<SUBNET>。 |
5.2 如何查找 BigQuery 项目 ID
在 Google Cloud 控制台 顶部点击项目下拉菜单,在弹出的项目列表中,每一行的 ID 列即为项目 ID(请注意区分 ID 与项目名称,二者通常不同)。

5.3 如何查找数据位置
进入 BigQuery Studio,在左侧 Explorer 中展开您的数据集,点击数据集名称,右侧详情面板中的 Data location 字段即为数据位置。

5.4 保存并测试连接
所有字段填写完成后,点击 保存 按钮,ABetterChoice 将自动发起一次连接测试:
- 连接成功:数据源列表中状态变为「已连接」,至此 BigQuery 连接配置完成,可以开始创建指标和实验。
- 连接失败:请根据弹窗中的错误提示,回到对应步骤检查授权、权限或填写内容是否正确。常见原因包括:服务账号未被授予 Token Creator 角色、数据集权限未授予、Project ID 或 Data Location 填错等。