配置统计引擎与样本校验
本页面回答一个核心问题:怎么让你 Results 页上看到的指标差异是可信的?
要让一个数字「可信」,只要两件事同时成立——
- 统计判定足够严谨:差异不是随机波动凑出来的(控制误判率)
- 样本本身可比:参与对比的两组用户在实验前是均衡的(控制采样偏差)
ABC 把这两件事拆成两个工具:统计引擎参数控制第 1 件事,实验回溯(Backtrack) 校验第 2 件事。两者在 Results 标签上同屏呈现,本页带你一次看完。
场景:一周后看板显示广告收入 +1.2%——是真有效,还是周末流量波峰的假象?光有 p 值不够——还要先确认两组样本是否可比。本页把这个完整判断流程讲透。
入口
统计引擎参数
打开实验的 Results 标签,在指标表上方点 Hypothesis testing parameters 图标,弹出小面板,包含三个设置项(显著性水平、统计功效、FDR)。
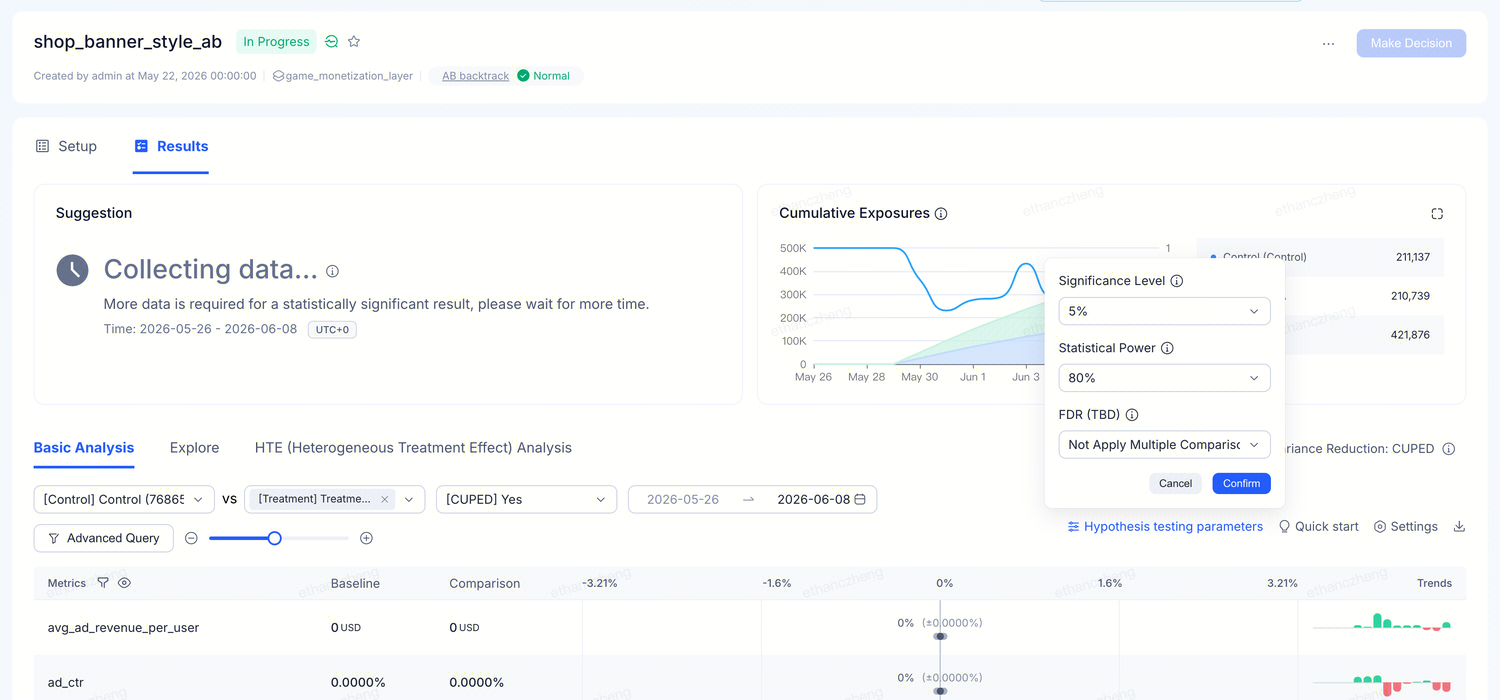
设置只影响当前的视图,不会改变实验本身。不同人可以用不同阈值看同一份数据,互不干扰。
实验回溯标签
实验详情页的 Setup 和 Results 共用的元数据栏上,有一个 AB backtrack 状态标签——这是平台自动跑的样本平衡校验结果。点击进入独立的回溯页面。
控制误判:三个核心设置
1. 显著性水平(Significance Level)
平台判定「显著」的严格程度。数值越低越严格——误报越少,但需要更多数据才能得出结论。
| 选项 | 适用场景 |
|---|---|
| 0.1% | 几乎不可能误报,适合流量极大、需近乎确定性的场景 |
| 1% | 决策成本高的场景,比如对付费玩家调价 |
| 5%(默认) | 标准选择,兼顾可靠性和出结论速度 |
| 10% | 早期探索,先拿方向性信号 |
游戏场景:测试新钻石礼包定价。定错价格意味着付费玩家的真金白银流失。设成 1%——宁可多等几天,也不要仓促决策。
2. 统计功效(Statistical Power)
当真实提升存在时,平台能检测到的概率。功效越高越灵敏,但需要更多数据。
| 选项 | 适用场景 |
|---|---|
| 60% | 可接受漏掉小效应,只想抓大变化 |
| 80%(默认) | 标准选择,能检测大部分有意义的效应 |
| 85% | DAU 很高时使用,可捕捉 +0.5% 级别的微小提升 |
游戏场景:超休闲游戏日活 50 万,样本量不是瓶颈。设成 85% 就能捕捉到新手引导优化带来的微小留存提升。
3. FDR 多重比较修正
同时看很多指标时,有些可能纯粹因为运气「看起来显著」。开启 FDR 修正可防止误判。
| 选项 | 适用场景 |
|---|---|
| 关闭(默认) | 只关注 1–2 个主指标,不需要修正 |
| 开启 | 同时查看 ≥ 3 个指标,希望确保被标显著的都是真实的 |
游戏场景:评估新签到奖励,同时看 D1 留存、D7 留存、DAU、广告展示、IAP 收入五个指标。五个里纯靠运气至少有一个「显著」的概率不低。开启修正后,仍显著的可放心采信。
加快出结论:CUPED 方差减少
CUPED 利用每个玩家实验前的行为数据过滤掉天然噪声——让你用同样玩家量、在更短时间得出结论。
在 Results 标签:
- 每个指标旁有 CUPED On / Off 标记
- 至少有一个指标启用时,顶部出现 Variance Reduction: CUPED 总标记
- CUPED 默认对所有支持的指标开启;某指标类型不支持时显示 CUPED Off 并给出原因
对休闲游戏的价值:玩家行为波动大——有人周末猛肝,有人每天一局。CUPED 用实验前基线消除天然差异。效果:实验可能 5 天就出结论,而不用等 12 天。
详见方差缩减。
样本可比性校验:实验回溯(Backtrack)
前三节解决了统计判定的严谨度。但严谨判定的前提是「样本本身可比」——如果实验组和对照组的用户构成本来就不一样(比如更多重氪玩家被分到了 Treatment),再严的 p 值也只是给假象套上「显著」标签。
实验回溯就是为这件事兜底——它在每个实验上自动跑,回答一个问题:
最近一段时间里,各变体之间的用户构成是否真的可比?
4 个常见使用场景
| 场景 | 业务背景 | 回溯告诉你什么 |
|---|---|---|
| 实验初期分流偏差 | 启动 2 天 Treatment_A 留存比 Control 高 5%,看起来是个胜利 | 标签 Normal → 5% 提升可信;非 Normal → 可能是分流刚启动时的偶然偏差 |
| 长跑实验中途漂移 | 实验跑 1 个月,整体 SRM 通过,但最近一周 Treatment 突然反转 | SRM 看不到近期漂移,回溯只看最近 3 / 7 天,能捕捉到客户端 bug、灰度不均等近期问题 |
| 临界结果犹豫不决 | p 值在 0.04~0.06 反复横跳 | 切到 7 天窗口对比 3 天差异方向是否一致、量级是否接近 |
| 刚补绑指标需要立即验证 | 担心新指标和老指标的样本基础不一致 | 点 Rerun Backtrack 立即重跑,几分钟出结果 |
回溯标签状态
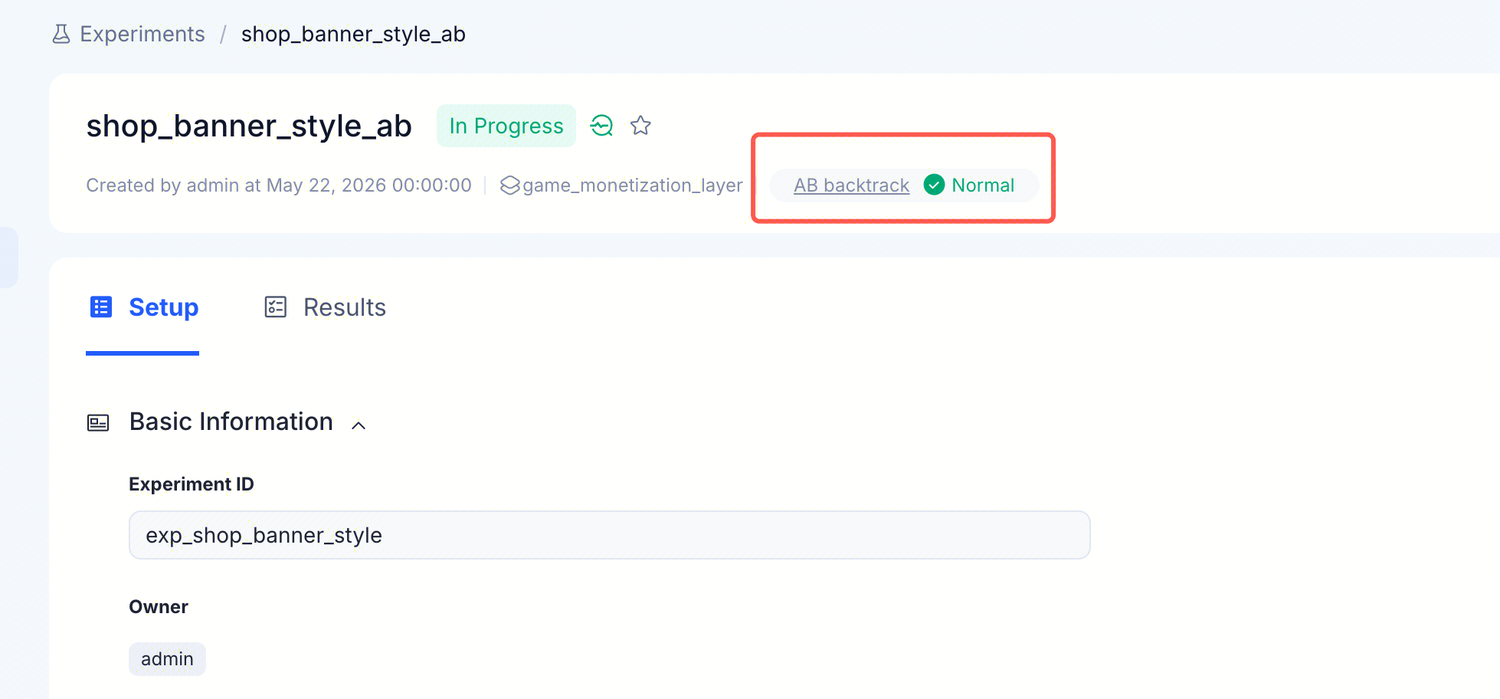
| 显示 | 含义 | 你该怎么做 |
|---|---|---|
- - | 还没有可呈现的回溯结果(新实验或还没有曝光) | 检查是否已绑定主指标 + 已累积曝光;都齐备后等几小时再看 |
✓ Normal | 最近一次回溯认为各变体之间是平衡的 | 可以信赖 Results 页的指标表 |
AB backtrack 字段带下划线、可点击——进入独立的回溯页面看详细对比。
四类信号串起来:标准决策检查表
实验结果是不是「真的可信」,要把 Results 页面上的几个信号一起读:
| 信号 | 它在告诉你什么 | 出问题怎么办 |
|---|---|---|
| AB backtrack 标签 / 页面 | 最近 3 / 7 天,各变体之间是否可比? | 切到 7-Day 看;非 Normal 时不要急着决策 |
| 样本比率失配(SRM) | 实验从开跑到现在整体上分流是否符合配置流量比? | SRM 不通过 → 检查分流配置 / 实验环境问题 |
| 统计引擎参数 | 当前阈值下是否足够严谨判定差异? | 调严显著性 / 开启 FDR 修正 |
| Suggestion | 平台综合判断给的下一步建议(决策 / 等待 / 补指标) | 按建议补齐数据再看 |
决策路径
依次过一遍,全过才算「可决策」:
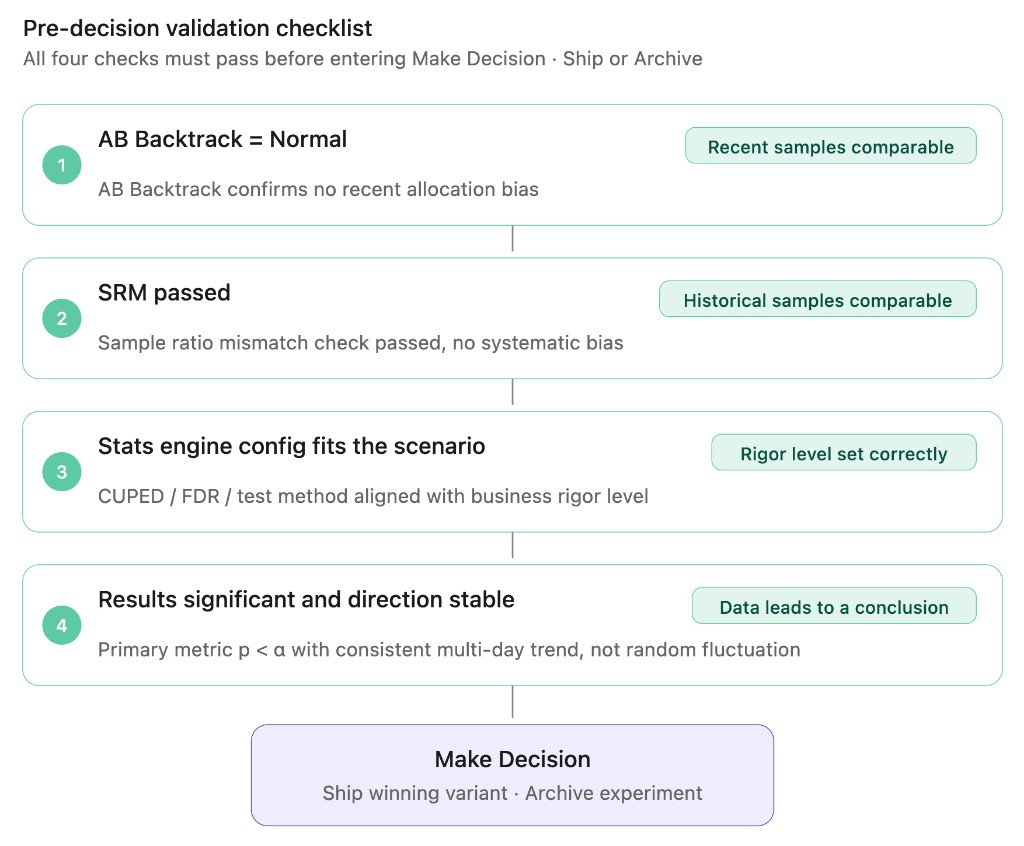
任何一项不通过,先解决再说决策。
推荐默认值
不确定时用默认值即可:
| 设置 | 默认值 | 什么情况下调整 |
|---|---|---|
| 显著性水平 | 5% | 付费相关实验收紧到 1%,早期探索放宽到 10% |
| 统计功效 | 80% | DAU 充足时提到 85% 捕捉微小提升 |
| FDR 修正 | 关闭 | 同时看 ≥ 3 个指标时打开 |
| CUPED | 自动开启 | 默认接受平台判断,不必手动调 |