受众概览
受众(Audience) 把一组用户筛选条件打包成一个有名字的对象。一旦定义好,项目里任意数量的实验和云控配置都可以直接按名字引用它——不需要每次重新写「设备 = iOS 且 App 版本 ≥ 1.8.0」这种条件表达式。
受众能解决的业务问题
场景 1:同一份人群,到处复用
背景:你定义了「高付费用户 = 累计付费 ≥ 100 元」。这群人会在多个地方用到——商品定价实验、广告频次实验、首充礼包配置、push 推送策略……
受众做法:在「受众管理」里建一次「高付费用户」,所有用到的实验和云控配置都直接选这个受众。业务定义统一:全公司的「高付费用户」永远是同一批人。
场景 2:业务定义变了,所有引用同步变
背景:老板今天说「累计付费 ≥ 100 元」标准太低,要改成 ≥ 200 元。
受众做法:改受众的圈选条件 → 所有引用它的实验 / 配置自动按新定义生效。无需挨个改各个实验配置——这是受众和「就地复制条件」最大的区别。
场景 3:精细化分群运营
背景:不同地区 / 平台 / 付费层级的用户运营策略不同。
受众做法:建一组互不重叠的受众——「日本用户」「韩国用户」「东南亚用户」「iOS 高付费」「Android 新用户」……云控配置规则按受众下发不同值,实验按受众独立调优。
核心能力
1. 建一次,到处用
业务定义统一是受众最大的价值。一个项目里的「高付费用户」「新版本用户」「日本玩家」一旦定义好,所有实验和配置共享同一份口径。
2. 改一处,所有引用同步变
业务标准变化时,只改受众规则——所有引用它的实验和配置自动按新定义生效。这是受众和「在实验里就地写条件」最本质的区别。
3. 在线实验占用时锁定,推荐复制新版本
平台保护机制:当受众正在被活跃实验引用时,规则编辑入口会被锁定,防止「改一改受众,所有跑着的实验目标人群全变了」这种事故。
推荐姿势:业务真要改受众规则时,复制一份新版本(如
paid_users_v2),改 v2,让新实验切到 v2;旧实验在 v1 上跑完再归档。
4. 关联引用反查
受众列表的 # of Experiments 列直接告诉你「哪些实验在用这个受众」——避免「这个受众还有没有人在用」的问题。
受众与其他对象的关系
受众构建在两个底层对象之上,又被两个上层对象使用:
| 层 | 对象 | 含义 |
|---|---|---|
| 底层 | 属性(Attribute) | 单个用户特征字段(如国家、App 版本、付费层级) |
| 中层 | 受众(Audience) | 由若干属性条件组合成的、有名字的人群规则 |
| 上层 | 实验 / 云控配置 | 引用受众来决定哪些用户在生效范围内 |
两端都是一对多:
- 一个受众可以引用多个属性
- 一个受众可以被多个实验 / 配置引用
反向问题——「哪些实验在用这个受众?」——受众列表的 # of Experiments 列直接给出。
在哪里管理
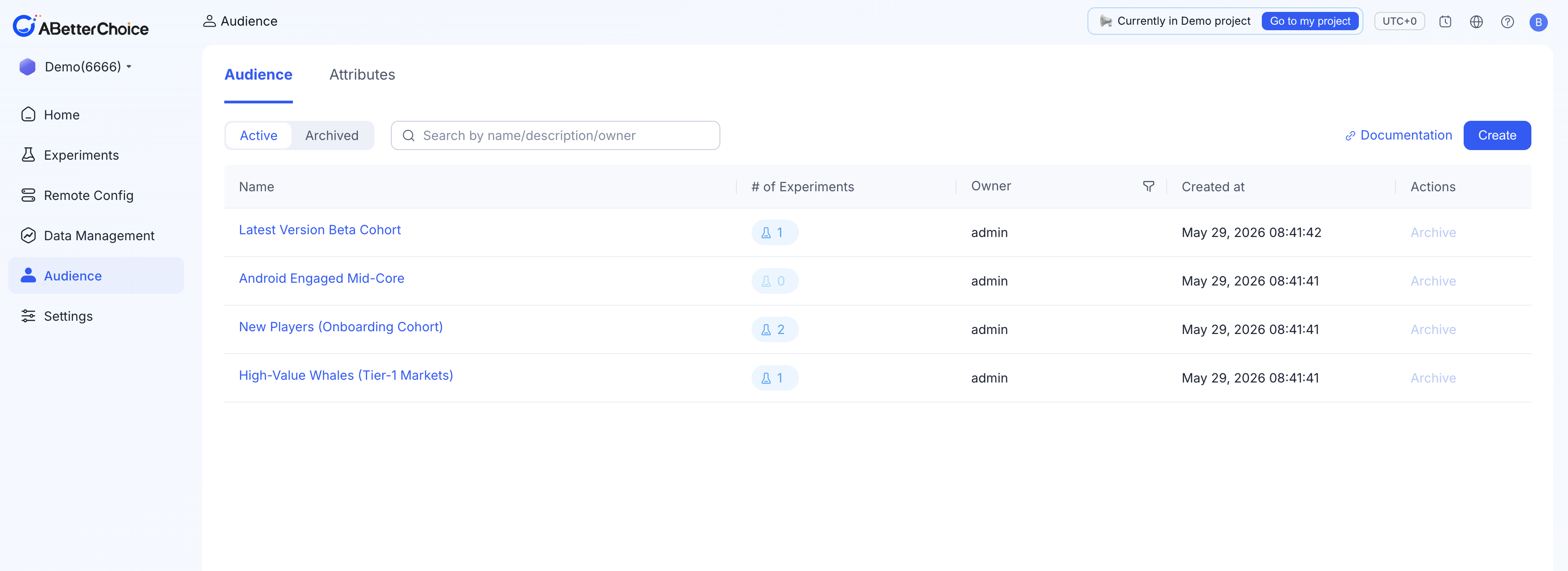 左侧导航点 Audience,页面有两个标签:
左侧导航点 Audience,页面有两个标签:
| 标签 | 内容 |
|---|---|
| Audience | 项目里所有具名受众。每行:名称、关联实验数、创建人、创建时间、Archive 操作 |
| Attributes | 构建规则时可选的属性目录。每行:名称、数据类型、创建人、创建时间、Archive 操作 |
两个标签共用顶部的 Active / Archived 过滤器和搜索框。
生命周期速览
受众的生命周期被刻意设计得很简短:创建后默认 Active,最终 Archive 退场。
| 状态 | 含义 |
|---|---|
| Active | 受众可被新实验 / 配置引用,参与求值 |
| Archived | 受众从默认列表隐去,不能再被新实验引用。存在在线实验/在线配置,则不支持归档 |
归档不是删除——受众的名字、规则、关联关系都保留,可以 Unarchive 找回。